Avoir bon caractère n’est pas donné à tout le monde. Mais avec l’Arduino, un caractère bien trempé est nécessaire !
Trêve de plaisanterie, voyons comment nos hiéroglyphes graphiques se sont frayés un chemin dans les ordinateurs entièrement numériques !
Les chaînes de caractères
Du texte, toujours du texte...
.
Par :
DIFFICULTÉ :★☆☆
Un peu d’histoire...
Depuis toujours, les processeurs, qu’ils soient simples comme les Atmel, ou complexes comme ceux de nos ordinateurs reposent tous sur des octets (des bytes en Anglais). Comment à partir de ces octets qui peuvent prendre n’importe quelle valeur entre 0 et 255 a-t-on pu y stocker des caractères ?
Il faut comprendre que les processeurs n’ont que faire de ces choses-là. Les caractères sont destinés à l’échange de données ou à l’affichage, par exemple pour être sûr que le nom de client du programme 1 est lu et interprété correctement par le programme 2, ou qu’un écran affiche correctement ce qu’on lui demande. Ainsi si je demande à un écran d’afficher les caractères correspondants à la suite d’octets 79 75, il faut qu’il utilise la même méthode de conversion, sinon au lieu de voir ’OK’, on risque d’avoir n’importe quoi !
Très tôt il a fallu décider d’une norme pour convertir n’importe quel caractère en octet et inversement. Les premiers ordinateurs reposaient sur une table de conversion appelée table ASCII (pour American Standard Code for Information Interchange). Cette table utilisaient 7 bits et donc des valeurs comprises entre 0 et 127.
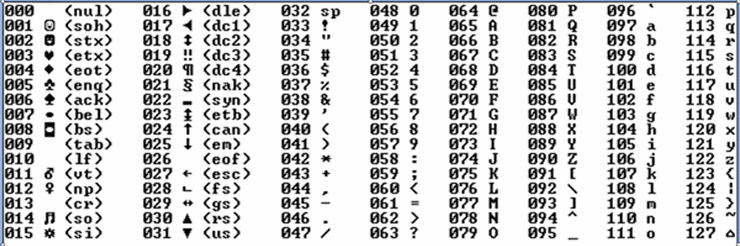
La première partie de la table comprise entre 0 et 31 comprend des caractères non graphiques de gestion. Par exemple une tabulation est représentée dans une chaîne par un 9. Le 10 correspond à un saut de ligne (Line Feed) tandis que le 13 est un retour chariot (Carriage Return). Si cette terminologie vous rappelle quelque chose, c’est normal. Sur une antique machine à écrire, pour passer à la ligne il fallait remonter le chariot tout à droite (Carriage return) en poussant le grand levier qui montait la feuille d’une ligne (Line Feed). Ces caractères sont encore utilisés aujourd’hui par les éditeurs de texte (Notepad, PSPad, Sublime Text, Emacs ...) pour représenter un passage à la ligne.

D’autres caractères particuliers sont présents dans cette zone, et pour beaucoup plus du tout utilisés, notamment toute la partie semi—graphique qui permettait de primitifs dessins sur des écrans purement texte :

- LOCODUINO écrit uniquement avec des caractères de la table ASCII !

Le code 32 est l’espace. C’est le premier caractère affichable (façon de parler...) de la table. Viennent ensuite les caractères de ponctuation et/ou particuliers comme les opérateurs arithmétiques de base ou les parenthèses, A partir de 48 nous avons les chiffres arabes. De 58 à 64, d’autres caractères spéciaux comme le ’@’ ou de ponctuation. Viennent ensuite les 26 lettres de l’alphabet latin en majuscule de 65 à 90. Encore d’autres caractères spéciaux, puis les minuscules latines de 97 à 122 pour finir par d’autres caractères spéciaux jusqu’à 127 qui n’est pas un caractère affichable.
à é ê ??
Les plus francophiles d’entre vous auront remarqué qu’à aucun moment il n’est question d’accent, de cédille et autre tréma... C’est que d’une part le standard a été édicté par des américains, et que d’autre part il n’y avait pas assez de place ! C’est pourquoi on a créé l’ASCII étendu qui repousse le nombre de caractères à 256. Mais là encore, pas assez de place pour loger toutes les variantes locales des caractères de tous les langages de la planète, même en se limitant aux alphabets latins... Alors on a fixé des variantes de la table ASCII pour les codes au delà de 127 selon la langue .
Et les autres ?
Bien sûr, nos amis russes, grecs et/ou asiatiques se sont réveillés et ont demandé à généraliser le concept pour y inclure leurs caractères exotiques. Après quelques tergiversations sur des caractères quelque fois sur 8 bits, quelque fois sur 16 (le MBCS), le standard Unicode a été publié. Aujourd’hui largement utilisé, il regroupe sur 16 bits, soient 65536 valeurs possibles, la table ASCII classique sur les 127 premiers caractères, puis tous les caractères locaux, les accentués latins, le Kanji, le Chinois, le Grec et tous les autres... La moitié seulement de l’espace disponible est utilisé, et si demain des Aliens nous rendent visite, une place leur est réservée !
Pour information, il y a au moins une table de conversion inventée par IBM pour ses mainframes et encore utilisée aujourd’hui pour les AS/400 , c’est l’EBCDIC (pour Extended Binary Coded Decimal Interchange Code). Cette table a été créée pour l’utilisation de cartes perforées, c’est ce qui explique sa forme peu orthodoxe.
Mais l’Arduino ?
Comme dit plus haut, l’Arduino en tant que tel ne gère que des octets et ne s’occupe pas de caractères. Les besoins sont donc fixés par l’interface utilisateur. Le premier et le plus connu des besoins est la console série. Lorsque vous voulez afficher ’OK’ sur cette console, vous utilisez Serial.println("OK"); . Cette instruction va transmettre les octets 79, 75 et 0 (on verra pourquoi un zéro en plus un peu plus tard...) à l’objet Serial qui va l’envoyer à son tour à une fenêtre de votre système (Windows, Mac, Linux...). Cette fenêtre va faire la conversion octet->ASCII et afficher OK ! On voit donc que si l’élément recevant les octets le décide, il peut afficher ce qu’il veut... Comment savoir à quoi correspond chaque code ASCII pour un Arduino ? Il suffit de coder un petit programme :
void setup()
{
Serial.begin(115200);
Serial.println(" 0 1 2 3 4 5 6 7 8 9");
Serial.print ("----------------------------------");
for (byte car = 30; car < 127; car++)
{
if (car % 10 == 0) // Le % ou 'modulo' donne le reste de la division entière.
{
Serial.println(""); // passe à la ligne
Serial.print(car, DEC);
if (car <100)
{
Serial.print(" :"); // Besoin d'un peu d'espace...
}
else
{
Serial.print(" :");
}
}
Serial.print(" ");
Serial.print((char) car);
Serial.print(" ");
}
}
void loop()
{}Il affiche dix lignes de dix caractères chacune. On va retrouver exactement la table ASCII simple telle que décrite plus haut. Si vous utilisez un écran LCD du commerce, vous retrouverez sans doute le même type de caractères.

Petit exercice : étendez maintenant l’affichage jusqu’à 255 pour inclure la fin de la table ASCII.
Un caractère c’est bien, une chaîne c’est mieux !
Pour une véritable chaîne de caractères, il faut créer un tableau de char :
char text[10];. Dans cette chaîne, vous pourrez mettre 9 caractères. Pourquoi neuf ? Parce que l’on a besoin de signaler la fin de cette chaîne. Cela découle d’un comportement de base des langages C et C++ : un tableau ne connait pas sa propre taille ! Même après avoir explicitement créé un tableau de dix caractères, vous pouvez écrire sans problème text[12] = 'E';. Il n’y aura pas d’erreur de compilation, pas de warning, rien qui vous permette de vous rendre compte immédiatement de votre méprise. Et le plus grave, c’est que ça va marcher ! Vous allez sans doute écraser quelque chose, peut être sans importance, peut-être pas... Mais l’emplacement mémoire text+12 contiendra bien le code ASCII de E, 69 .
Une chaîne de caractères en C, c’est toujours la liste des caractères suivie d’un octet à zéro qui matérialise la fin réelle de la chaîne. Si vous voulez une chaîne de dix caractères maximum, il vous faut réserver la place pour onze octets : char text[11]; .
Faire du traitement de texte...
Manipuler une chaîne revient à manipuler un tableau en s’assurant que son contenu ne dépasse pas la taille maximale, et que la liste des caractères est bien terminée par un zéro.
Créons une nouvelle chaîne :
void setup()
{
char text[10];
text[0] = 'B'; // on peut aussi écrire avec le code ASCII text[0] = 66;
// mais c'est (un peu) plus clair comme ça !
text[1] = 'o';
text[2] = 'n';
text[3] = 'j';
text[4] = 'o';
text[5] = 'u';
text[6] = 'r';
text[7] = 0; // on s’arrête là. Ce qui se trouve derrière le 0 n'a pas d'importance.
}On obtiendra la même résultat avec
void setup()
{
char text[10] = "Bonjour";
}Le compilateur comprend grâce aux guillemets qu’il s’agit d’une chaîne et va tout seul ajouter le zéro. C’est quand même plus lisible. Cette syntaxe ne fonctionne que pour la déclaration de la variable. Notez l’utilisation de simple quote (sous la touche 4 d’un clavier Azerty) pour un seul caractère, alors qu’on utilise le guillemet (sous le 3 du clavier) pour une chaîne de caractère, même si elle n’en comprend qu’un seul !
On peut même faire plus simple et ne pas spécifier la taille du tableau :
void setup()
{
char text[] = "Bonjour";
}Le compilateur connait la taille de la chaîne à mettre dans text et va ajouter le zéro tout seul. Seule la mémoire nécessaire sera utilisée.
Trouver la vraie longueur d’une chaîne n’est pas compliqué :
int len(char inText[])
{
int length = 0;
while (inText[length] != 0)
length++;
return length;
}Tant que l’on n’a pas atteint le zéro, on incrémente le compteur. Dès qu’il est atteint, on retourne le compteur. On voit bien que si le zéro a été oublié, on risque de tourner longtemps et de parcourir toute la mémoire !
Si on utilise cette petite fonction, ajouter deux chaînes existantes n’est pas très compliqué :
void ajoutechaine(char inDest[], char inSource[])
{
int lenDest = len(inDest);
int lenSource = len(inSource);
for (int pos = 0; pos < lenSource; pos++)
{
inDest[lenDest+pos] = inSource[pos];
}
// On oublie pas la fin !
inDest[lenDest+lenSource] = 0;
}On ajoute à la fin de la première chaîne (inDest[inDest + pos]) le caractère de la nouvelle chaîne (inSource[pos])
On ne va pas continuer comme ça pour vous démoraliser... Les compilateurs C ont depuis longtemps pris en charge les chaînes de caractères classiques via un jeu de fonctions standardisées qui gèrent toutes le zéro de fin correctement. Le principe reste le même, c’est juste qu’il n’est pas nécessaire de réinventer la roue à chaque fois...
Pour les utiliser vous devez ajouter #include <string.h> à votre croquis. Les fonctions en question sont celles-ci :
- size_t strlen(const char *text) renvoie la longueur (
size_test un entier...) . - char *strcpy(char *dest, const char *source) copie le contenu de
sourceà la place dedest. La fonction retourne le pointeurdest. Leconstsignifie que l’argument n’a pas le droit d’être modifié par la fonction. - char *strcat(char *dest, const char *source) copie le contenu de
sourceà la fin dedest. La fonction retourne le pointeurdest. Attention à la taille de la somme des deux ;destdoit pouvoir contenir les deux chaînes bout à bout, plus le zéro ! - int strcmp(const char *text1, const char *text2) Comparer deux chaînes n’est pas simple. Ecrire
text1 == text2ne compare que les valeurs des pointeurs qui sont très probablement différents... Pour bien comparer, il faut faire une boucle et comparer les caractères un par un jusqu’au zéro de fin. Cette fonction le fait pour vous. La valeur de retour est soit 0 si ce sont les mêmes, soit 1 ou -1 selon que la première a un code ASCII plus élevé ou moins élevé que la seconde chaîne à la première différence. - char *strlwr(char *source) convertit la chaîne en minuscules (lower case). Vu la structure de la table ASCII, passer en minuscule revient à ajouter 32 au code du caractère.
- char *strupr(char *source) convertit la chaîne en majuscules (upper case). Il faut là retirer 32...
Il en a d’autres, en particulier les mêmes que celles-ci avec un argument supplémentaire de longueur maxi pour éviter de planter si le zéro est absent. Leur nom commence souvent par strn au lieu de str. Je vous laisse le plaisir de les découvrir.
Mais tout ça encombre la mémoire !
Le problème des chaînes de caractères, c’est que ça prend de la place ! Et la place, c’est une denrée rare sur nos petits processeurs. Si vous ajoutez un nouveau texte dans votre source
char text[] = "Bonjour Locoduino";
void setup()
{
Serial.begin(115200);
Serial.println(text);
}
void loop()
{
}Il va occuper 18 octets (le texte plus le zéro de fin) de mémoire SRAM très précieuse parce que très limitée. Je vous laisse imaginer si toute une ergonomie utilisant des dizaines de textes doit être faite sur un écran, ou si vous voulez discuter par la liaison série par des commandes textes par exemple. Pour économiser la SRAM, il y a une astuce propre à l’Arduino (cela n’existe pas en C/C++) permettant d’envoyer les déclarations constantes dans la mémoire programme généralement moins remplie :
const char text[] PROGMEM = "Bonjour Locoduino";
Le const est là pour garantir que le contenu de cette chaîne ne sera jamais modifié. Mais c’est bien le mot clé Arduino PROGMEM qui va permettre au compilateur de stocker ce texte dans la mémoire programme. Le tableau ( ;) ) serait idyllique si il n’y avait pas une petite contrepartie. Pendant l’exécution, un pointeur de données est toujours un pointeur sur de la mémoire en SRAM. Comme ce n’est pas le cas de ces pointeurs PROGMEM, il faut passer par une phase de récupération des données. Ce qui signifie que l’on ne peut pas se servir de text comme d’habitude. Il faut passer par une fonction de récupération strcpy_P :
const char text[] PROGMEM = "Bonjour Locoduino";
void setup()
{
Serial.begin(115200);
char buffer[50];
strcpy_P(buffer, text);
Serial.println(buffer);
}
void loop()
{
}La taille de buffer doit être suffisante pour accueillir le contenu de text avec son zéro de fin.
Même lorsque vous utilisez une chaîne de caractères constante comme argument de fonction, comme un appel à Serial.print() par exemple, la mémoire nécessaire au stockage de cette chaîne par le compilateur est prise sur la SRAM, la mémoire vive, et pas sur la mémoire programme.
// Test avec 30 caractères.
Serial.println("0123456789012345678901234567890123456789");La compilation pour un Uno donne ça :
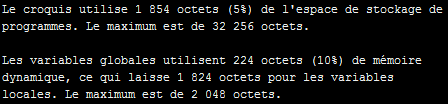
Heureusement, il y a aussi une syntaxe directe pour stocker ces chaînes particulières dans la mémoire programme directement :
// Test avec 30 caractères.
Serial.println(F("0123456789012345678901234567890123456789"));Ce qui donne :
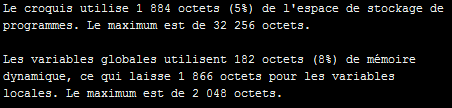
On voit que la mémoire programme a grossi de trente octets, tandis que les variables globales stockées dans la SRAM (limitée à 2048 octets sur le UNO) ont diminué du même volume !
Pour pouvoir bénéficier de cette fonctionnalité, la fonction doit être capable de gérer un argument de type const __FlashStringHelper *, ce qui est le cas de toutes les méthodes de la classe Serial par exemple.
Ces différents moyens de stockage (PROGMEM, F("") ) et d’accés à la mémoire programme (strcpy_P et d’autres pour les entiers, les doubles...) sont bien entendus dédiés à l’Arduino et n’existent pas pour d’autres plateformes, comme les programmes Windows, Linux ou iOs...
Gérer des chaînes de caractères dans un programme Arduino n’est pas compliqué. Il faut juste avoir conscience de la façon dont le processeur les perçoit...